
공대생 정리노트
Recovery System(1) 본문
Reference
http://www.kyobobook.co.kr/product/detailViewEng.laf?mallGb=ENG&ejkGb=ENG&barcode=9781260084504
Database System Concepts - 교보문고
www.kyobobook.co.kr
Storage
DB에서 스토리지는 3가지로 나눌 수 있다.
- Volatile storage
-
Non-Volatile storage
-
Stable storage
volatile storage
volatile storage 안의 정보들은 시스템 크래시가 발생하면 일반적으로 살아남지 못한다.
메인 메모리나 캐시 메모리가 해당된다.
volatile storage로의 접근은 굉장히 빠른데, 메모리 접근 자체가 그 자체로 빠를 뿐더러 volatile storage의 어떤 데이터든 directly하게 접근할 수 있기 때문이다.
Non-volatile storage
non volatile storage의 정보들은 시스템 크래시 발생 이후에도 살아남을 수 있다.
하드 디스크나 플래시 메모리와 같은 2차 스토리지가 해당된다.
stable storage
stable storage에 있는 정보는 절대 소실되지 않는다.
stable storage를 구현하려면 우리는 여러 non-volatile storage에(보통은 disk) replicate를 해놓는다.
RAID 시스템이 한 예이다.
Data access
데이터베이스는 block이라는 고정된 길이의 단위로 나뉘어진다.
-
physical block : 디스크와 메인 메모리간 오퍼레이션들은 블록 단위로 이루어진다. 디스크에 저장된 블록이 physical block
-
buffer block : 메인 메모리에 일시적으로 저장된 블록
-
disk buffer : 메모리에 저장된 블록들의 영역
디스크와 메인 메모리간 블록 움직임은 다음과 같다
-
input(B)는 physical block B를 메인 메모리로 옮긴다
-
output(B)는 buffer block B를 디스크로 옮기고 적절한 physical block과 교체한다.
우리는 두 개의 오퍼레이션으로 데이터를 옮긴다
-
Read(X) : 데이터 아이템 X의 값을 지역 변수 xi에 할당한다.
-
Write(X) : 지역 변수 xi의 값을 buffer block 의 X에 할당한다.
buffer block이 버퍼 매니저가 메모리가 필요하거나 데이터베이스가 B의 변경을 디스크에 반영하기 위해 디스크에 써지는 경우가 있다. 이것을 데이터 시스템이 output(B)를 통해 buffer B를 force-output 했다고 말한다.
Recovery and Atomicity
Log Records
데이터베이스 수정을 기록하는데 가장 많이 사용되는 구조는 log이다.
log는 log records로 이루어져 데이터베이스의 모든 업데이트 활동을 기록한다.
log record에는 여러 타입이 있고, update log record는 single database write을 의미한다.
update log record는 다음의 field를 가지고 있다.
-
transaction identifier : write operation을 만든 트랜잭션의 unique identifier
-
Data-item identifier : written된 데이터 아이템의 unique identifier. 보통 데이터 아이템의 디스크 위치이고, 블록 identifier와 블록 내부의 오프셋으로 이루어진다.
-
Old value : write되기 전 이전 값
-
New value : write된 후의 값
update log record는 <Ti,Xj, V1,V2> 로 표현가능하다(트랜잭션 Ti가 데이터 아이템 Xj에 write을 하고 값 V1이 V2로 바뀐다.
-
<Ti start> : 트랜잭션 Ti가 시작
-
<Ti commit> : 트랜잭션 Ti가 커밋됐다
-
<Ti abort> : 트랜잭션 Ti가 aborted 됐다
트랜잭션이 write을 수행하면 데이터베이스가 수정되기 전에 log record가 생성되고 log에 추가된다.
log record가 존재하면 우리는 우리가 원할때 데이터베이스에 수정을 output할 수 있고, 이미 데이터베이스에 output된 사항을 되돌릴 수 있다. old value 필드를 이용하면 가능하다.
Database Modification
트랜잭션은 log record를 데이터베이스를 수정하기 전에 만든다.
log record들이 트랜잭션이 abort되는 상황에서 undo하게 해주거나 디스크에 있는 DB에 반영이 되기 전 시스템이 크래시가 났을 때 redo할 수 있게 해준다.
트랜잭션이 데이터를 수정하는 과정
-
트랜잭션이 메인 메모리의 private part에서 계산 과정들을 수행한다
-
트랜잭션이 메인 메모리의 디스크 버퍼의 데이터 블록을 수정한다
-
데이터베이스 시스템이 데이터 블록을 디스크에 쓰기 위해 output operation을 수행한다
트랜잭션이 디스크 버퍼를 업데이트 했거나 디스크를 업데이트 하는 경우 트랜잭션이 데이터베이스를 수정한다고 한다. 메인 메모리의 private part를 업데이트 하는 것은 데이터베이스를 수정한다고 하지 않는다.
만약 트랜잭션이 커밋되기 전까지 데이터베이스를 수정하지 않는다면 deferred modification 테크닉을 쓴다고 한다.
트랜잭션이 active할 때 데이터베이스 수정이 일어나면 immediate modification 테크닉을 쓴다고 한다.
deffered modification 테크닉은 업데이트된 아이템들에 대해 로컬 카피를 만들어야 해서 오버헤드가 있다. 트랜잭션이 업데이트된 데이터를 읽으려고 하면 로컬 카피에서 읽어와야 한다.
recovery 알고리즘은 여러 상황을 고려해야하고, 다음과 같은 부분까지도 고려해야 한다.
-
트랜잭션이 커밋되었지만 일부 데이터베이스 수정이 메인 메모리의 디스크 버퍼에만 있고 디스크에는 반영이 되지 않은 경우
-
트랜잭션이 active한 상태에서 데이터베이스를 수정했지만 뒤 과정에서 failure가 발생해 abort해야 하는 경우
undo : 로그 레코드의 old value를 이용해 명시된 데이터를 old 값으로 바꾸는 것
redo : new value를 이용해 명시된 데이터를 새 값으로 바꾸는 것
Concurrency control and recovery
concurrency control scheme을 허용하면
데이터 아이템 X가 트랜잭션 T1에 의해 수정되고 T1이 커밋되기 전 T2에 의해 수정될 때, T1을 undo하기 위해 X를 old value로 복구하면 T2도 undo가 된다.
이러한 상황을 피하기 위해 recovery 알고리즘은 데이터 아이템이 트랜잭션에 의해 수정될 때 커밋이나 abort되기 전까지 다른 트랜잭션이 수정하지 못하게 한다
이는 two-phase locking이 필요하다.
Transaction Commit
트랜잭션의 최신 로그 레코드인 커밋 로그 레코드가 안정한 스토리지로 output 되었을 때 커밋되었다고 한다.
이때 모든 로그 레코드들은 안정한 스토리지로 output 되어 있는 상태여야 한다.
시스템 크래시가 발생했을 때 트랜잭션이 redo될 수 있는 충분한 정보를 제공한다.
만약 로그 레코드에 <Ti commit>이 stable storage로 output되기 전에 시스템 크래시가 발생하면 트랜잭션 Ti는 롤백되야 한다.
Using the Log to Redo and Undo Transactions
은행 시스템을 생각해보자.
T0는 A계좌에서 B 계좌로 50달러를 옮긴다

T1은 C계좌에서 100달러를 인출한다
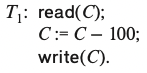
Recovery scheme은 두 recovery 과정을 사용한다.
-
Redo(Ti) : 트랜잭션 Ti의 새 값으로 모든 데이터 아이템들의 값을 업데이트 한다. redo에서 업데이트들의 순서는 중요하다. 대부분의 복구 알고리즘에서 redo의 각 트랜잭션을 분리해서 실행하지 않는다.
-
undo(Ti) : 트랜잭션 Ti의 old value로 모든 데이터 아이템들의 값을 업데이트한다.
시스템 크래시가 발생하면 시스템은 원자성을 지키기 위해 어떤 트랜잭션이 redo되고 undo되야 하는지 결정한다
-
트랜잭션 Ti가 <Ti start>가 있지만 <Ti commit> 혹은 <Ti abort>가 없다면 undo되어야 한다
-
트랜잭션 Ti가 <Ti start>가 있고 <Ti commit> 혹은 <Ti abort>가 있다면 redo되어야 한다.
-
<Ti abort>는 undo operation이 만든 redo only record이다. 그래서 최종 결과는 Ti의 수정을 undo 하는 케이스 일 것이다.
-
Ti abort는 중복을 만들지만, 복구 알고리즘을 단순화해 전체 복구 시간을 빠르게 해준다.
-
-

19.4.(a) : T0의 write(B) 이후 크래시가 발생했을 때 트랜잭션 T0는 안정한 스토리지에 written 되어 있다. 시스템이 돌아왔을 때 <T0 start>는 찾았지만 <T0 commit> 혹은 <T0 abort>는 찾지 못했으므로 T0는 undo 되어야 한다. 이 결과로 디스크 안의 A와 B는 각각 1000달러, 2000달러로 복구된다.
19.4.(b) : 트랜잭션 T1의 Wirte(C) 이후 crash가 발생한 시나리오다. 시스템이 돌아왔을 때 두 개의 복구 액션들이 필요하다. undo(T1)과 redo(T0)이 수행되어야 한다.
19.4.(c) : T1 커밋 이후 crash가 발생한 경우다. redo(T0), redo(T1)
Checkpoints
시스템이 크래시가 나면 로그를 보고 어떤 것을 redo할지, 어떤 것을 undo할 지 결정해야 한다.
모든 로그에 대해 작업을 하면 좋겠지만 모든 로그를 보는 것은 시간이 오래 걸리며, redo의 경우 대부분 이미 데이터베이스에 반영이 되어 있다.
이러한 오버헤드를 줄이기 위하여 checkpoint를 둔다.
체크포인트가 수행되면 다음 과정이 일어난다
-
메인 메모리에 존재하는 모든 로그 레코드들을 안정한 스토리지로 output한다.
-
디스크에 모든 수정된 buffer block을 output한다.
-
안정한 스토리지로 <checkpoint L> 형태의 log record를 output한다. L은 checkpoint의 시간에 액티브한 트랜잭션의 리스트이다.
체크포인트 진행중에는 어떤 업데이트 action을 수반하는 트랜잭션도 수행되면 안된다.
시스템이 크래시가 발생하면 가장 최신의 체크포인트 <checkpoint L> 레코드를 찾는다. L에 존재하는 모든 트랜잭션의 redo 또는 undo는 적용이 되어야 하고, L 이후의 모든 트랜잭션도 적용이 되어야 한다. 적용되어야 하는 트랜잭션들의 셋을 T라고 표시하자.
-
T의 모든 트랜잭션들 중 커밋 또는 abort가 없는 것들을 undo가 되어야 한다
-
커밋 또는 abort가 있다면 redo가 되어야 한다.
L의 모든 트랜잭션보다 일찍 시작한 트랜잭션들은 더이상 필요가 없다. (이미 완료가 되었으니까)
이런 로그 레코드들은 데이터베이스가 공간이 필요할 때 지워진다.
'로드맵 > DB' 카테고리의 다른 글
| mongdoDB 내부 캐시 (1) | 2022.01.27 |
|---|---|
| mongoDB - 배열 인덱싱 (0) | 2022.01.25 |
| SQL VS NoSQL (0) | 2020.08.30 |
'로드맵/DB' Related Articles
more
